In questa lezione parleremo dei cookie HTTP, file di informazioni di piccola dimensione, usati per migliorare la nostra esperienza durante la navigazione in Rete.
Abbiamo detto che il protocollo HTTP è stateless. Quindi se, ad esempio, un client fa una richiesta di una pagina web e subito dopo la richiede nuovamente, il server non è in grado di capire che le richieste avvengono dallo stesso client.
Ad esempio se utilizziamo un sito dove dobbiamo accedere alle pagine private tramite autenticazione, dovremmo fare l’autenticazione per ogni pagina.
Grazie ai cookie (letteralmente biscotto) è possibile fare in modo che gli utenti non debbano autenticarsi di volta in volta. Questa pratica è presente in tutti i siti di commercio elettronico o in molti siti che richiedono un’autenticazione, come ad esempio forum.
Quindi l’utilizzo dei cookie rende l’HTTP un protocollo non più stateless, ma stateful (con stato).
I cookie sono dunque utilizzati per recuperare informazioni sul lato client e memorizzarli sul server web a lungo termine.
Cookie e privacy
Quindi i server web, assieme alla risposta, inviano anche i cookie al web client (browser). Il browser del client può memorizzarlo e poi inviarlo nelle richieste successive al server.
In questo modo il server web può monitorare le attività degli utenti e quindi anche le visite effettuate ai siti web. Spesso molte aziende utilizzano i cookie per mandare messaggi pubblicitari mirati, in base alle abitudini degli utenti. In questo caso si parla infatti di cookie di profilazione.
Questo comporta una violazione della privacy dell’utente che naviga in Internet.
Ormai è obbligo informare l’utente che il sito web utilizza i cookie, anche solo per monitorare il traffico. Di solito compare un banner informativo, che richiede l’accettazione dei tipi di cookie utilizzati e la presa visione della legge sulla privacy.
È possibile non accettare i cookie, ma è possibile che alcune funzionalità del sito non funzioneranno correttamente.
Una VPN (virtual private network) consente di creare una connessione sicura tra un client ed i sever web. Infatti quando si usa una VPN il traffico dati passa in un tunnel virtuale criptato e dunque sicuro, attraverso il quale non si possono intercettare i pacchetti dei dati trasmessi nella rete.
Vantaggi uso VPN
I vantaggi nell’uso di una VPN sono tanti, ne evidenziamo alcuni:
– Anonimato: l’indirizzo IP non è visibile e neanche la posizione dalla quale avviene il collegamento. Infatti, nel momento in cui ci si connette ad un server web, l’indirizzo che quest’ultimo vedrà sarà quello del server VPN. Inoltre molti provider VPN non tengono completamente traccia dei collegamenti effettuati dai client, quindi difficilmente sarà possibile risalire alle visite effettuate su Internet. Ma ricordiamo sempre che non c’è un modo che garantisce totalmente di non poter essere rintracciati su Internet.
– Sicurezza: utilizzare una connessione criptata riesce a garantire maggiore sicurezza nella connessione, contribuendo a tenere lontano i criminali informatici. Infatti in una rete VPN si utilizzano dei protocolli sicuri a cui sono stati applicati algoritmi crittografici.
– Evitare la profilazione: grazie alla VPN i dati sono criptati. Di solito le aziende pubblicitarie raccolgono i nostri dati, cercando di capire le nostre abitudini, per mostrare poi messaggi pubblicitari inerenti le nostre ricerche su Internet. In una rete VPN sicura, le aziende non possono risalire ai nostri dati e dunque alle nostre ricerche nella rete.
– Accessibilità ai siti web bloccati: con la VPN si utilizzano indirizzi IP che possono consentire la visualizzazione di servizi e siti che altrimenti sarebbero bloccati.
Usi della VPN
Una VPN può essere utilizzata ad uso personale per garantire la sicurezza nelle proprie connessioni. In particolare, si raccomanda di farne uso nelle reti Wi-Fi pubbliche, dove sono più frequenti gli attacchi da parte di hacker.
Una VPN può essere usata anche da molte aziende che ad esempio consentono lo smart working. In questo modo, infatti, si può entrare nella rete locale criptata e sicura, dopo aver effettuato l’autenticazione, sfruttando il tunnel virtuale. Così è possibile condividere cartelle e file tra i colleghi di lavoro in maniera sicura.
Come utilizzare una VPN
Per poter utilizzare una VPN occorre scegliere un provider affidabile.
Dopo occorre fare pochi semplici passi:
– scaricare il software ed installarlo sul nostro dispositivo.
– impostare le opzioni di navigazione sicura.
In questo modo il software cripta le richieste inviandole al server VPN. Il server VPN decripta i dati e invia le richieste ai server web per ottenere una risposta. Una volta ottenuta la risposta il server VPN cripta nuovamente i dati per inviarli sul tuo computer, che verranno nuovamente decriptati per poter essere comprensibili.
In JavaScript, le variabili e le costanti svolgono un ruolo fondamentale nella memorizzazione e manipolazione dei dati. Introdurremo anche il concetto di costante nel contesto di JavaScript, evidenziando l’uso della parola chiave const.
Dichiarazione in JavaScript di Variabili e Costanti
Nel contesto di JavaScript, è comune utilizzare la parola chiave const per dichiarare costanti e let per dichiarare variabili. La principale differenza tra const e let è che le costanti, una volta assegnato loro un valore, non possono essere riassegnate, mentre le variabili possono.
// Esempio di costante con const
const pigreco = 3.14;
// Esempio di variabile con let
let raggio = 4, area;
area = pigreco * raggio * raggio;
document.write(`L'area del cerchio di raggio ${raggio} è: ${area}`);
In questo esempio, pigreco è una costante e raggio è una variabile. La variabile area viene utilizzata per memorizzare il risultato di un calcolo.
In JavaScript, la parola chiave const è utilizzata per dichiarare costanti. Tuttavia, a differenza di altri linguaggi, il significato di “costante” in JavaScript è più flessibile. Pur restando immutabile nel senso che non può essere riassegnata, una costante può ancora contenere un oggetto mutabile, come un array o un oggetto.
const listaNumeri = [1, 2, 3, 4, 5];
listaNumeri.push(6); // Consentito, poiché l'array è mutabile
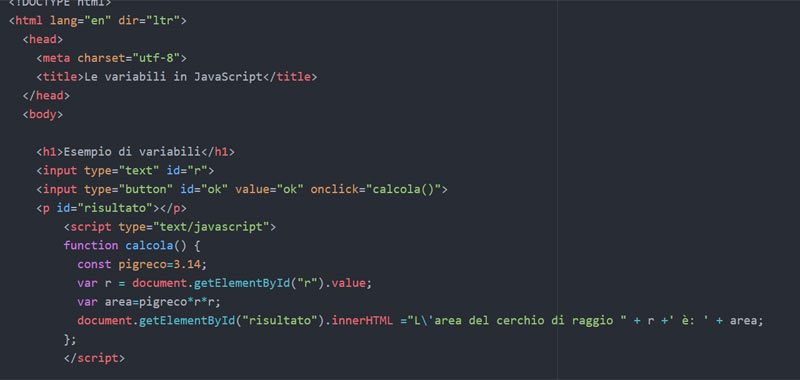
Facciamo dunque un esempio Interattivo:
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>JavaScript Variabili e Costanti</title>
<script>
function calcola() {
const pigreco = 3.14;
let raggio = document.getElementById("raggio").value;
let area = pigreco * raggio * raggio;
document.getElementById("risultato").innerHTML = `L'area del cerchio di raggio ${raggio} è: ${area}`;
}
</script>
</head>
<body>
<h1>Esempio di variabili e costanti in JavaScript</h1>
<label for="raggio">Inserisci il raggio:</label>
<input type="text" id="raggio">
<input type="button" id="calcola" value="Calcola" onclick="calcola()">
<p id="risultato"></p>
</body>
</html>
In questo esempio interattivo, gli utenti possono inserire il valore del raggio e calcolare l’area del cerchio. Il risultato è poi visualizzato dinamicamente sulla pagina.
Ulteriori esempi: calcolo della media
// Secondo Esempio: Calcolo della Media
var a = 5, b = 6;
let somma = a + b;
let media = somma / 2;
document.write(`La media dei numeri ${a} e ${b} è ${media}`);
Uso di variabili e costanti in JavaScript
Cerchiamo di capire cosa utilizzare. La scelta tra var, let e const in JavaScript dipende dallo scopo d’uso e dalla natura della variabile che si sta dichiarando.
var:
Scopo di Funzione: Le variabili dichiarate con var hanno uno scope di funzione. Ciò significa che sono visibili all’interno della funzione in cui sono dichiarate e possono essere accessibili anche prima della loro dichiarazione (a differenza di let e const).
Hoisting: Le dichiarazioni di var vengono “sollevate” (hoisting) durante la fase di esecuzione. Questo significa che la variabile può essere utilizzata prima della sua dichiarazione.
Riassegnazione: Le variabili var possono essere riassegnate.
var x = 10;
if (true) {
var x = 20; //la stessa variabile x è riassegnata
}
console.log(x); // Output: 20
let:
Scopo di Blocco: Le variabili dichiarate con let hanno uno scope di blocco. Ciò significa che sono visibili solo all’interno del blocco in cui sono dichiarate.
Hoisting: Anche se let è soggetto a hoisting, non può essere utilizzato prima della sua dichiarazione. Viene “sollevato” ma rimane non inizializzato fino alla dichiarazione effettiva.
Riassegnazione: Le variabili let possono essere riassegnate.
let y = 10;
if (true) {
let y = 20; //nuova variabile creata all'interno del blocco
}
console.log(y); // Output: 10
const:
Scopo di Blocco: Le variabili dichiarate con const hanno uno scope di blocco.
Assegnazione Iniziale Obbligatoria: Una variabile const deve essere assegnata con un valore durante la sua dichiarazione e non può essere riassegnata successivamente.
Immunità alla Riassegnazione: Le variabili const non possono essere riassegnate dopo la loro inizializzazione. Tuttavia, questo non implica immutabilità per oggetti e array dichiarati con const. Gli elementi interni di tali strutture dati possono comunque essere modificati.
const z = 10;
// z = 20; // Errore! Non può riassegnare una variabile const dopo l'inizializzazione
Quando Usare let, var o const
Utilizza const quando il valore della variabile rimarrà invariato durante l’esecuzione del tuo programma. È una buona pratica utilizzare const per dichiarare costanti.
Utilizza let quando si sa che il valore della variabile cambierà durante l’esecuzione e si ha bisogno di uno scope di blocco.
Usa var solo se si sta lavorando con codice più vecchio o se si hanno delle ragioni specifiche per farlo, poiché let e const sono opzioni più recenti e spesso più sicure.
In generale, è dunque preferibile utilizzare const per dichiarare variabili quando possibile, poiché promuove l’immobilità del valore, rendendo il codice più chiaro e meno soggetto a errori. Utilizziamo invece let quando la riassegnazione è necessaria, e cerchiamo di evitare var a meno che tu non stiamo lavorando con codice più vecchio (legacy) che non supporta let e const.
Seguiamo le convenzioni di nomenclatura JavaScript, che è il camelCase per variabili e costanti.
Tipizzazione Dinamica delle variabili
Parliamo anche di tipizzazione dinamica. Infatti in JavaScript, le variabili sono dinamicamente tipizzate, il che significa che il loro tipo può cambiare durante l’esecuzione del programma.
JavaScript inoltre esegue automaticamente la conversione di tipo quando è necessario durante le operazioni.
Facciamo degli esempi:
let numero = 10;
let testo = "5";
let somma = numero + testo; // La conversione automatica di tipo trasforma il numero in una stringa
console.log(somma); // Output: "105"
In questa lezione abbiamo parlato di variabili e costanti in JavaScript, nella prossima lezione parleremo di istruzioni condizionali e faremo degli esempi.
Un proxy HTTP, definito anche proxy server, è un server utilizzato per lo scambio di messaggi tra un client ed un server, come una sorta di intermediario.
I client richiedono al proxy server un servizio come ad esempio una pagina web, un file audio/video o qualsiasi altra risorsa che risiede su altro server.
L’obiettivo finale è dunque quello di filtrare il traffico web. Molte aziende si avvalgono dei proxy per effettuare un controllo sulla rete.
Perché utilizzare questo intermediario?
Motivi per utilizzare un proxy HTTP
Ecco, di seguito, alcuni motivi per utilizzare un proxy HTTP:
Privacy: Mantenere l’anonimato durante una connessione, come nel sistema Tor (software che consente di navigare in Internet nell’anonimato, dunque protegge la privacy degli utenti che navigano nella rete), dove i dati non transitano dal client al server direttamente ma passano dai server Tor. Ma il proxy, non cripta la connessione come fa invece la VPN, quindi si occupa solo di fornire un indirizzo IP diverso. Il server web che riceve una richiesta da parte di un client, vede l’indirizzo IP del proxy e non quello del client.
Caching: Un proxy può essere utilizzato per velocizzare le richieste di servizi da parte dei client. Infatti i caching proxy conservano, per un certo tempo, i risultati delle richieste da parte di un client. Questo rende più veloce i tempi di risposta delle stesse risorse da parte di altri client. Ecco perché molte aziende utilizzano un caching proxy. Nel momento in cui ci sono state delle modifiche alle pagine web, allora il server proxy richiede nuovamente la pagina al server web.
Monitoraggio: un proxy server consente di monitorare le pagine web visitate, consentendo di effettuare statistiche, ma violando la privacy degli utenti. Ecco perché ci sono delle norme per ogni sito web che avvisano gli utenti dell’utilizzo di mezzi per monitorare il traffico web.
Amministrazione: grazie ad un proxy server si possono stabilire delle regole, come ad esempio bloccare facilmente alcuni siti. Dunque si determina facilmente quali richieste inoltrare e quali rifiutare in base a determinate regole.
Può succedere però che un proxy invii al server web anche l’indirizzo IP del client, tutto dipende dalla configurazione del proxy. In tal caso si dice che il server web si fida del proxy server sulle informazioni che sta fornendo, perché non ha modo di verificare.
Tipi di proxy
NOA (Non Anonimus Proxy): sono i proxy più utilizzati dagli ISP, per rendere gli accessi ai siti web più veloci e dunque risparmiare la banda di connessione. Sono proxy non anonimi infatti mostrano l’indirizzo IP reale del richiedente. Il server web li riconosce facilmente.
ANM (Anonimus Proxy): sono i proxy anonimi che non trasmettono l’indirizzo IP del client, ma trasmettono l’indirizzo IP del proxy. Questo tipo di proxy non nasconde il fatto che la comunicazione sta facendo uso di un proxy.
HIA (High Anonimus Proxy): sono i proxy altamente anonimi che nascondono l’IP del client e sono difficili da riconoscere da parte del server web.
Proxy distorcenti: offrono una maggiore protezione perché trasmettono un IP casuale, quindi il server web vede le richieste provenienti da indirizzi IP diversi.
Il protocollo HTTP (HyperText Transfer Protocol) è utilizzato per la trasmissione di informazioni sul web.
La prima versione di questo protocollo è stata implementata nel 1991.
Il funzionamento di HTTP è basato su un meccanismo di richiesta/risposta, quindi di tipo client/server.
Infatti il client che corrisponde al browser effettua una richiesta al server per ottenere un determinato contenuto (pagina html, immagine, CSS, ecc).
In definitiva quindi ci sono due messaggi HTTP, i messaggi di richiesta e quelli di risposta.
Quando la richiesta viene soddisfatta le porte in genere vengono chiuse, cosa che non avviene con altri protocolli come ad esempio l’FTP.
Per porta (socket) si intende il punto di accesso ad un server da parte di uno o più client. Chiaramente non è una porta fisica ma logica, virtuale.
Le porte sono indicate con dei numeri a 16 bit, dunque ci sono 2^16=65536 porte, cioè da 0 a 65.535.
Ogni numero identifica una determinata applicazione, infatti in questo modo si garantisce che i dati vengano indirizzati al processo corretto.
Nel caso del protocollo HTTP la porta di riferimento è la 80. Quindi un server web (come ad esempio Apache), attende la richiesta di contenuti su questa porta.
HTTP è un protocollo stateless, cioè senza memoria, questo per poter andare da un server all’altro velocemente attraverso i collegamenti ipertestuali.
Infatti per ogni nuova richiesta effettua una nuova connessione al server web, che come dicevamo prima, viene subito chiusa.
Protocollo HTTP e metodi
Abbiamo detto che il client invia delle richieste al server e lo fa utilizzando dei metodi come primo parametro. I metodi sono GET, HEAD, POST, introdotti già dalla prima versione HTTP 1.0. Successivamente sono stati introdotti i metodi PUT e DELETE. Infine con la versione attuale HTTP 1.1 sono stati introdotti i metodi OPTIONS, TRACE, CONNECT.
I browser moderni supportano principalmente i metodi GET e POST. Elenchiamo di seguito alcuni metodi tra quelli citati.
Metodo GET
Il metodo GET è quello più importante e richiede una risorsa ad un server. Questo è il metodo che si attiva quando specifichiamo un url in un browser web o quando facciamo click su un collegamento ipertestuale di una pagina html. Con questo metodo non si possono cancellare i dati su un server o modificarli.
Metodo HEAD
Questo metodo è simile a GET, ma il server risponde inviando solo gli header relativi, senza il corpo. Quindi il metodo HEAD non carica la risorsa come file, immagini, ecc.
È un metodo usato per la diagnostica, ad esempio per verificare la validità di un URI (Uniform Resource Identifier), cioè per vedere se la risorsa richiesta esiste. Oppure per verificare l’accessibilità di un URI, ad esempio la risorsa esiste e non ha bisogno di autenticazione. Infine può essere utilizzato per vedere se la risorsa, nel frattempo, è stata modificata.
Metodo POST
Questo metodo serve per trasmettere informazioni dal client al server, infatti viene utilizzato ad esempio per inviare dati di un form al server web.
Metodo DELETE
Questo metodo elimina la risorsa identificata dall’URL specificato.
Metodo Put
Metodo utilizzato per trasmettere delle informazioni dal client al server, sostituendo la risorsa specificata. Questo metodo serve ad esempio per fare l’upload di un file su un server web, creando o sostituendo il file esistente.
Risposta ad un richiesta
Il server risponde con un codice di stato.
Di seguito alcuni esempi di codici di stato:
100 Continue – La richiesta effettuata dal client è parzialmente compilata, cioè ad esempio ancora non ha trasmesso il corpo della pagina.
200 Ok – Richiesta eseguita con successo, cioè tutto è stato eseguito nel modo giusto.
204 No content – Richiesta eseguita con successo ma senza restituire un contenuto.
301 Moved permanently– La risorsa esiste ma non è identificata correttamente, è stata spostata permanentemente.
400Bad Request – Richiesta errata, cioè la richiesta non è comprensibile al server web.
401Unauthorized – Cioè la richiesta non è autorizzata in quanto occorre autenticarsi.
404 not found – Risorsa non esistente.
500 Internal Server Error – Errore generico del server.
Quindi i codici di stato che iniziano con:
– 1 Indicano dei messaggi informativi.
– 2 Indicano successo, cioè il server ha accettato la richiesta del client ed è stata eseguita correttamente.
– 3 Indicano che la risorsa è stata spostata (ridirezione).
Per HTTPS (HyperText Transfer Protocol Secure) si intende un protocollo per la comunicazione sicura, in quanto i dati sono criptati. Ciò è un requisito importante soprattutto nei siti di e-commerce, infatti i dati degli utenti come ad esempio i numeri della carta di credito o altre forme di pagamento, sono crittografati. In questo modo i malintenzionati non possono accedere facilmente a questi dati.
HTTPS utilizza dunque il protocollo HTTP + il protocollo TLS (Transport Layer Security), versione più aggiornata e sicura del precedente SSL.
La porta utilizzata è la 443. Quindi ad esempio per andare sul sito https://www.codingcreativo.it il vostro browser web ha contattato il server web sulla porta 443.













Commenti recenti